编码世界的基石:Unicode 和 UTF-8
2025-10-14
平时聊天都会用到 emoji。
估计很少人知道,其实 emoji 并不是图像,而是一种特殊的“文字”。
我们生活的这个世界,很辽阔,有众多国家,形形色色的民族,古老而又绵延不绝的语言。如何让每个人,在互联网上都能平等地使用自己熟悉的文字,是个大问题。
Unicode 和 UTF-8 解决了这个问题。
1. 背景
和人类不同,计算机只认识 0 和 1,完全没有文字的概念。
基于 0 和 1 构建文字的过程,叫作编码。
计算机诞生之初,只能处理英语。大家都知道,英语的字母比较有限,于是 ASCII (American Standard Code for Information Interchange,美国信息交换标准代码) 编码被发明出来,用一个字节中的 7 位(一个字节有 8 位),表示最多 128 个字符。
比如字母 A 在表中第 65 位,二进制表示为 0100 0001。
计算机解读时,以字节为单位,看到 0100 0001,就知道是字母 A。
在英语的世界里,一切都很好。
但是伴随计算机的发展和普及,问题出现了?非英语国家的人怎么用?
于是各个国家纷纷定制本国的编码方案,比如:
-
中国大陆有 GB2312、GBK、GB18030
-
台湾有 BIG5
-
日本有 Shift-JIS
各自为政的结果,是各种编码方案之间并不兼容。
常见的“锟斤拷”的例子,即源于此:原始编码是 UTF-8,但被错误地当作 GBK(或其他编码)来读取。
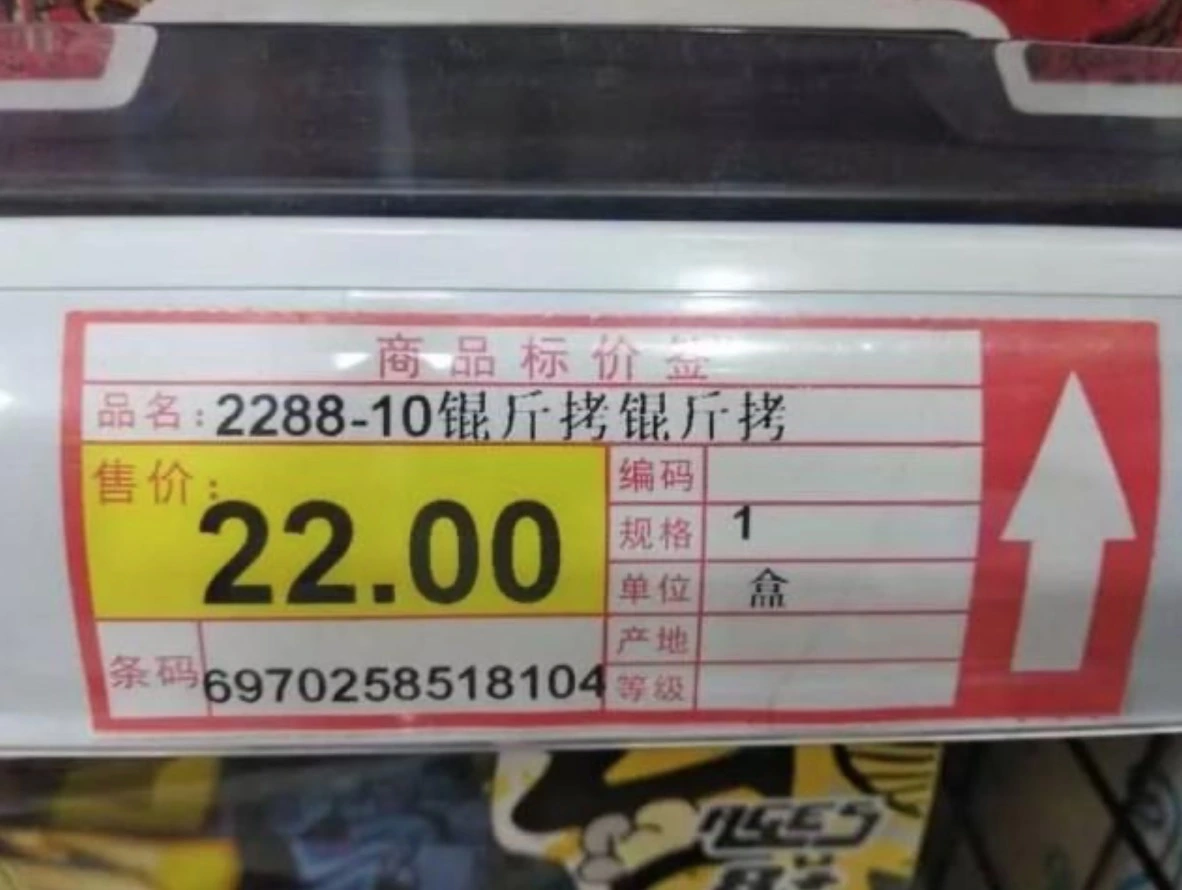
有问题的地方,自然会有解决方案。这样的事在计算机领域里屡见不鲜。
鉴于种种乱象,Unicode 联盟在 1991 年提出了统一的标准——Unicode。
Unicode 的诞生,宣示着群雄逐鹿的终结,一种更高维度的编码方案一统天下。
2. Unicode
本质上讲,Unicode 只做了一件事,就是为万物统一命名。
自人类学会如何使用语言以来产生的几乎所有符号,都可以在 Unicode 中找到对应,甚至涵盖:
-
数学符号
-
音乐符号
-
表情符号(emoji)
每个字符都有一个唯一“编号”,叫做 码点(Code Point),写法是 U+xxxx,可以简单理解为一个数字。例如:
- 英文字母
A是U+0041 - 中文 “中” 是
U+4E2D - 😀 表情是
U+1F600
与 ASCII 的 7 位不同,Unicode 将编码空间划分成 17 个平面,每个平面包含 65,536 个码位,总计 1,114,112 个。
完全够世界人民用了!
当所有人都认这套编码规则时,就不会发生“乱码”的情况。这就是标准化的意义,最大限度地节约使用成本。
3. UTF-8
但是,仅仅只有 Unicode 是不够的。
Unicode 编码指的是将符号转化为某个数字,而计算机编码则是将数字转化为一个二进制表示。
常见的计算机编码 Unicode 的方式有三种:
- UTF-32:每个字符固定用 4 个字节存储,简单直接,但非常浪费空间
- UTF-16:大多数字符用 2 个字节存储,但有些(比如表情符号)要用 4 个字节
- UTF-8:一种变长编码,每个字符需要 1 到 4 个字节不等
事实上,UTF-8 以它的简洁和灵活,成为最流行的编码选择。说个冷知识,UTF-8 的发明人,便是 Unix 和 Go 语言之父——Ken Thompson。
UTF-8 的成功可简单归为以下三种原因:
-
兼容 ASCII:
- 英文字符(0~127)只用 1 个字节,与 ASCII 完全一致,不会出现前向兼容问题
-
节省空间:
- 英文只占 1 字节
- 常见的中文占 3 字节
- 生僻字、表情符号占 4 字节
-
无歧义:
- UTF-8 有明确的编码规则,解析时不会混淆
既然 UTF-8 是一种变长的字符编码规则,如何有效区分两个字符的边界便成了一个关键问题。
UTF-8 使用至多 4 个字节表示,其中对于任意字节:
- 如果第一位为 0,则独立的表示一个字符( ASCII 码)
- 如果第一位为 1,第二位为 0,则为一个多字节字符中的一个字节(非 ASCII 字符)
- 如果前两位为 1,第三位为 0,则为两个字节表示的字符中的第一个字节
- 如果前三位为 1,第四位为 0,则为三个字节表示的字符中的第一个字节
- 如果前四位为 1,第五位为 0,则为四个字节表示的字符中的第一个字节
以 A (U+0041) 为例:
U+0041二进制是0100 0001- 在 UTF-8 下,它只用 1 个字节存储,刚好就是
0100 0001
再看中文 “中 (U+4E2D)” :
U+4E2D二进制是0100 1110 0010 1101- 在 UTF-8 下,它需要 3 个字节:
11100100 10111000 10101101
边界信息,隐藏在第一个字节中,依次便可知晓后续所有变长编码的长度。
4. 总结
Unicode 解决的是一个标准化的问题,用一套“编号”规则,统一世界上所有语言,彼此不会碰撞。所有人都认可,沟通起来就简单。
UTF-8 则是该“编号”系统在计算机中的落地,兼顾空间效率的同时保证编码有效,看似复杂,其实规则很清晰。
现在的互联网空间,Unicode 和 UTF-8 几乎已经成为通用规则,“乱码”的乱象很少再见到。
在我们安然享受网络带来的诸多便利时,绝对想象不到,那些看似简单事情的背后,隐藏着多少聪明头脑的闪光时刻。
时间不言,但证明了一切。
(完)
参考
- 本文作者:Plantree
- 本文链接:https://plantree.me/blog/2025/unicode-utf8/
- 版权声明:所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
最后更新于: 2025-12-02T05:24:46+08:00